
Only very rarely will the quality of software improve with a rewrite: Instead, you will most likely lose features no stakeholder remembers anymore (usually about 40 per cent) and the implementation will take way more time than anticipated. Furthermore, implementing new features during a rewrite is often impossible, if you don’t set up a new team which in turn will have less knowledge of and insight into the existing software quality.
Automated tests are the easiest way to make sure you don’t lose any functionality. Automated tests are often equated with unit tests, though, which usually can’t be written for old code. It’s those outdated structures making unit tests hard to write: static method calls, singletons and static registries are still widely used, making code difficult to test while at the same time posing the reason why you should refactor at all. A vicious cycle!
Course of action
Automated tests are not identical to unit tests. Other kinds of tests like integration tests, acceptance tests and functional tests can also be automated! For refactoring purposes, it’s the functional tests which can be of great assistance. They are utilized to make sure a piece of software executes specific functions or tasks. You might, for instance, test a web application to checkout if a checkout process in an online shop still works fine. The process you want to test will be executed as a whole in the test. This is how it works:
- A use case for an application is specified in a functional test.
- You make sure the code to be refactored is covered by the test.
- You refactor that code.
- You write unit tests for important new pieces of code.
If you follow these steps, they will ensure the use case included in the test is still working after refactoring. How to adjust and clean up code will be discussed below. Unit Tests for new, clean code should be written immediately!
Visit our IPC ’17 Sessions with a focus on Testing & Quality
Simple functional tests
There are many ways to create functional tests for websites, fulfilling different requirements as to the difficulty of creating those tests, maintaining them and keeping them stable. In our experience the optimal solution for use cases like this is to utilize a combination of PHPUnit and Mink. The tests we are talking about don’t need to work for a long time, but will be used exclusively while code undergoes refactoring. You can usually delete them afterwards and replace them with something more sensible. When it comes to stable and maintainable functional tests, requirements are quite different; at least some refactoring of frontend code is required before implementing them.
Listing 1 illustrates how a functional test for a successful login-procedure could look like. The visible parent class FeatureTest derives from PHPUnit_Framework_TestCase – this way tests will be integrated with other, existing tests in PHPUnit. Mink, the framework for browser tests, is initialized by the baseclass and provides some simple helper methods. Full code can be found in our app example.
Listing 1
class LoginTest extends FeatureTest
{
use FeatureTest\UserHelper;
public function testLogin()
{
$user = $this->createUser('kore', 'password', '[email protected]', 'Kore Nordmann');
$page = $this->visit('/');
$page->find('css', '#username')->setValue('kore');
$page->find('css', '#password')->setValue('password');
$page->find('css', '#submit')->press();
$page = $this->session->getPage();
$this->assertNotNull(
$welcomeBox = $page->find('css', '.welcome'),
'Login failed'
);
$this->assertContains("Hello Kore", $welcomeBox->getText());
}
}
It’s rather obvious what this code does. The Mink API for browser control allows for many other interactions to be executed. In most cases it is best to use CSS Selectors to address virtually any element you like in an existing website. In Listing 1, the first two form fields get filled out with data of a user account specified before; afterwards the form will be send by confirming the corresponding button. Next, the test will check whether the next page displays the welcome text. If it doesn’t, some error must have occurred.
On the other hand, this kind of weak error handling illustrates some typical issue with functional tests: if a single test fails, you will most likely get no information on the reason for that error – this is a major difference to unit tests. After a functional test failed, the problem needs to be singled out by usual debugging processes. But if it’s just about ensuring you don’t break features while refactoring, this test will work. Most problems will have been caused right before they show up by whatever you did throughout the refactoring process. That kind of makes finding the source easy, doesn’t it?
How does Mink work?
Mink can work with different browser emulators (Zombie.js, Goutte) or browser remote controls (Selenium, Sahi). Especially the latter kind helps tremendously with manually monitoring and debugging test execution. Browser emulators, though, are way faster in executing tests, being quite useful for fast verification. Mink abstracts between different backends involved, so you can also use both at the same time, as long as you don’t need any special features.
- Goutte: Goutte is a browser-side implementation written in PHP, ultimately just executing HTTP-Requests. Correspondingly, JavaScript used in frontend won’t work.
- Zombie.js: Zombie.js simulates a headless browser – therefore you don’t need a graphical output system, making this solution work smoothly on servers, just like Goutte.Zombie.js can even interpret JavaScript!
- Sahi/Selenium: Both are popular frameworks for working with real browsers, which for one is helpful for watching test execution, but also assists with testing views and JavaScript in different browsers. In our experience, Sahi works better with applications using a lot of JavaScript.
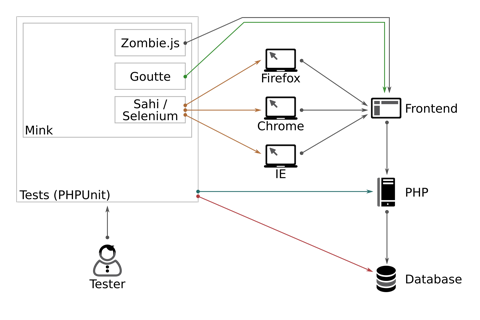
In figure 1 you can see the differences described above. Goutte and Zombie.js will access the frontend of you web application without intermediary (green, grey), Selenium and Sahi use a browser to execute tests (orange).
In the end, PHPUnit-Tests are just PHP-Code and nothing more, so we can immediately access the application code from the tests (blue) – at least if it runs on the same machine. Therefor you can execute operations straight at the database (red), like resetting or adding data sets. However, it is also possible to develop dedicated services for adding data to an application for testing (listing 1) – they, again, will have direct access to database and application.
Services
Setup of functional tests is easy and fast; there remains one problem to be solved though: the tested website most likely interacts with external services like databases and web services (REST, SOAP, …) for payment, newsletter or some other functionality. Most websites that need to be refactored don’t have sufficient level of abstraction in the code for this kind of services; therefore, you can’t just exchange them for testing.
Running functional tests against a test system is highly recommendable since we want to adjust the code in the next step. The optimal solution is to use a virtual machine; if that is not possible, a staging system can be sufficient too. However, that might be problematic especially when several developers are working on the code at the same time. If there are no such testing systems yet, generating them is necessarily the first step. You can also automatize setup processes at the same time if possible (Ansible, Chef, Puppet, …) – but don’t underestimate the amount of effort you need to put into that. Strategies for handling external services can be of different kind and will most likely be in line with established manual testing strategies. Some services (payment) will offer test accounts that won’t trigger any real action – you might want to use those, seriously! Many databases are just too large to be reset completely every time you run a test. Correspondingly you need to find an optimal solution in the local environment to handle test data. It might help to work with new, random user names, to reset just particular tables or selectively delete all data that was added after a specific date, if there is such an option.
However, there will still be some services from time to time, which get accessed by so many instances in your code, that are woven so tightly into the code, that none of these strategies work. In this case you should first hide the services behind an abstraction layer so you can test other aspects of the system and refactor them. Later on we will look into how to refactor these services. C.f. the paragraph on Branch by Abstraction.
Code Coverage
Code Coverage usually indicates which parts of the code have not yet been subjected to unit tests; you don’t want to mess up these statistics, so functional tests and integration tests won’t account for your code coverage. However, in our case we actually can divert code coverage from its intended use.
When writing functional tests for our application, we want to make sure our tests actually cover all the code to be refactored. To do so, we can use XDebug to record our code coverage server-side while the tests are executed. Be aware the functional tests usually consist of many different calls, so the individual code-coverage-reports need to be merged afterwards. A library offering functionality for both recording and merging of the collected information into an HTML-report is PHP_CodeCoverage.
This leads us to the following course of action:
- Identify code to be refactored
- Write functional tests covering this code
- Test for code coverage to make sure, you really covered all the code – if not, go back to step 2.
When executing these steps on code with a long history, you will probably run into code not accessible anymore. Keep in mind some code isn’t made to be accessed online, but there might be other ways: cronjobs, command line scripts. If your code can’t be accessed on either of these ways, just get rid of it immediately. You can still restore it from version control is necessary.
- Renaming:
- Extract Method: it can also help with making code easier to read if new methods get extracted from old ones that are very long. Inside a method, Code blocks with additional comments are good places to start. In the best case, you can extract so called “pure methods” – they don’t have side effects, because they don’t access class variables or global state. Pay attention to the variables written and read when extracting code though. IDE support for this step is just about moderate.
- Extract Class:
- Extract Component:
Correction of Name and Identifier can be of tremendous help to make code more readable. Many names might not be correct anymore for historical reasons or at least have become inconsistent. Side effects like interactions with other parts of the code can easily result from that. Luckily, IDEs like PHPStorm nowadays offer a good support for changing names.
after successful extraction of some methods, you most likely will see the outlines of method groups belonging together. Those can be extracted in separate classes now. Be careful with the class variables you use! IDEs offer some rudimentary support for this at most, since new classes especially need to be made available in all corresponding locations – for example by the utilized dependency injection container.
when several classes have been extracted, you sometimes notice some group of them actually is better represented as a separate component or library. You could transfer those to a separate project; but I don’t know of any automated support for this.
After the steps Extract Method and especially after Extract Class, it’s often useful to write tests for the code that got extracted. These tests are the ones that can survive over a long period of time. “Pure methods” mentioned above are especially easy to test, because you don’t need any test doubles.
As mentioned above, some of the steps can be automated by using tools like IDEs. However, they might be prone to errors and need to be checked manually, due to PHP’s weak and dynamic typing. Besides well-established IDEs, there are also some CLI-tools trying to help with implementing these changes, which you can use irrespective of your IDE of choice.
Branch by Abstraction
When doing large refactorings of long established software, a central point of interest stems from certain back ends (web services, databases, …), that got access to all parts of the code. Or there might be implicit logic, representing central business logic, being distributed all through the code. Branch by Abstraction is a suitable approach to refactor such aspect.
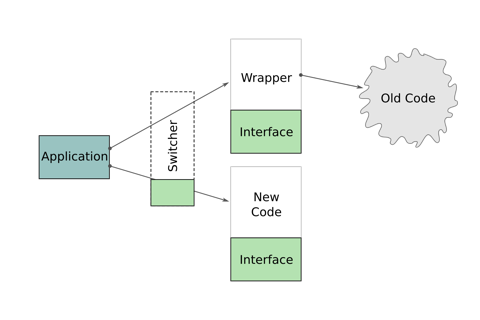
Figure 2 illustrates the basic idea of locating all instances of these kinds of access. Every access will be extracted into a wrapper class that will execute calls to the original old code. It is important not to change the code yet but just introduce indirections to notably increase the probability of not breaking anything.
After localising all instances and replacing the code everywhere, you can now simplify the API of the wrapper class. In doing so, you should define an Interface for this wrapper – don’t change the old code yet! This alone generates some value, because the code executing the call will be significantly easier to read. Most times, many lines of code can be replaced by a comprehensible access to the wrapper class.
After the interface was defined, you can start working on a new implementation if that is still necessary at all. This new implementation just needs to fit the requirements of the interface we just defined.
Especially when working with complex systems that were extracted this way, it might be necessary to add verification beyond the tests already written. By following the approach outlined above, you can add another implementation of the interface that will use both the old and new interfaces and compare the results. If the new implementation reacts the same as the old one in most cases, you can be sure the implementation works right. GitHub worked like this to first verify the implementation of their merge-algorithm before exchanging it.
Finally, you can eventually remove all old pieces of code, with the new code resolving all requests. But even if you just execute step one, your code will be easier to read.
Advice
At the end, let me give you two further pieces of advice regarding refactoring that proved to be quite helpful with our customers to get fast and good results. Let me first remind you of what I said before: Commit early and often.
However, especially when working on large projects, you should not commit to feature branches as it is regularly done on Git. Code advancements make it hard to impossible to re-integrate them back with the master branch, doubling the amount of work. When working in small, non-invasive steps, code will always stay functional, opening up the possibility to work on master branch; this also adds value to all other developers involved immediately.
When you want to refactore complexe code or do a rework of complex concepts in your code, it might be a good idea to not just work with pair programming but to skip to mob programming instead. With all developers involved in the project working together on one large monitor, virtually all errors will be recognized instantly. Furthermore, this facilitates a common understanding of the code and changes that get executed. Final clean up can be done afterwards in small groups.
There is still a question of the goal of refactoring to be answered. Sometimes the goal is made obvious by external influences, sometimes certain parts of the application hurt so much everyone just knows what needs to be done. Generally speaking, you should be familiar with concepts like S.O.L.I.D. and Clean Code to make sensible changes. Furthermore, there are the lists of typical code problems and solutions to them, everyone knows what I’m talking about here – but that would go beyond the scope of this article.
Conclusion
Functional tests are excellent resources to make sure your code keeps working throughout refactoring. Working with our customers, we have successfully realized this approach in projects that couldn’t be developed further or even fixed anymore before. The method outlined in this article works also for large codebases and very complex products. Refactored Code can increase productivity substantially, without the need to stop advancements for a long time.





